Vector Search Explained for SEO Teams (And How to Optimize for It)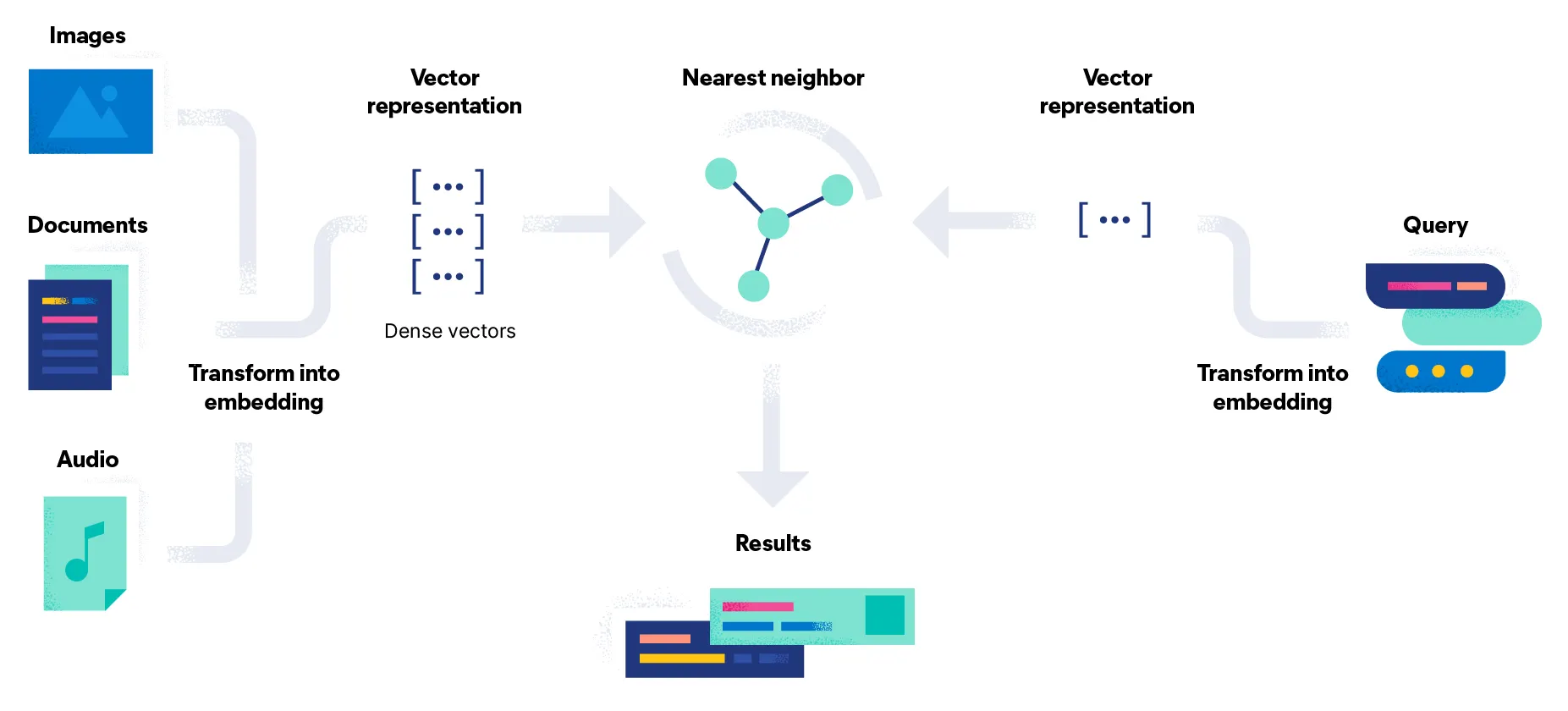
Foundational for LLM-driven retrieval and semantic indexing
If you’re an SEO professional who’s been following the AI revolution in search, you’ve likely encountered terms like “vector search,” “embeddings,” and “semantic indexing” with increasing frequency. These aren’t just technical buzzwords—they represent a fundamental shift in how search engines understand, index, and retrieve content. As AI-powered search platforms like ChatGPT, Perplexity, Google’s SGE, and enterprise RAG (Retrieval-Augmented Generation) systems become mainstream, understanding vector search is no longer optional for SEO teams. It’s essential.
This guide demystifies vector search, explains how it powers modern AI search systems, and provides practical optimization strategies that SEO teams can implement immediately to ensure their content remains discoverable in this new paradigm.
What Is Vector Search? (And Why Traditional Search Is Insufficient)
To understand vector search, we first need to recognize the limitations of traditional keyword-based search that SEO professionals have optimized for over the past two decades.
Traditional Keyword Search: The Old Paradigm
Traditional search engines rely primarily on lexical matching—finding documents that contain the same words as the query. Even with sophisticated variations like stemming (finding “running” when searching for “run”), synonym matching, and TF-IDF weighting, these systems fundamentally match text strings.
This approach has significant limitations:
Vocabulary mismatch problems: If your content uses “automobile” but users search for “car,” traditional systems struggle to connect them without explicit synonym mapping.
Context blindness: The word “apple” in “apple pie recipe” versus “Apple stock price” requires context to disambiguate, which keyword matching handles poorly.
Semantic gaps: Conceptually related content may share no common keywords. An article about “reducing carbon footprint” might be highly relevant to someone searching “fight climate change” despite minimal keyword overlap.
Query reformulation burden: Users must try multiple keyword combinations to find relevant content, creating friction and frustration.
Vector Search: The Semantic Revolution
Vector search solves these problems by representing both content and queries as mathematical vectors in high-dimensional space. Instead of matching words, vector search matches meaning.
Here’s how it works conceptually:
Numerical representation: Every piece of content gets converted into a vector—essentially an array of numbers (typically 768, 1024, or 1536 dimensions for modern models). These numbers capture the semantic meaning of the content.
Semantic proximity: Content with similar meanings produces similar vectors, even if they use completely different words. “Automobile safety features” and “car crash protection systems” would have vectors close together in vector space.
Distance-based retrieval: When a user submits a query, it’s also converted to a vector. The system finds content vectors closest to the query vector, retrieving semantically relevant results regardless of keyword overlap.
Multi-dimensional understanding: Each dimension in the vector can represent abstract semantic features learned from massive text corpora—things like topic, sentiment, formality, technicality, and countless other linguistic patterns.
This fundamental shift means SEO teams must think beyond keywords to semantic optimization—ensuring content is semantically rich, contextually clear, and comprehensively covers topics in ways that produce strong vector representations.
Vector Embeddings: The Technical Foundation
To optimize for vector search, SEO teams need a working understanding of embeddings—the technology that makes vector search possible.
What Are Embeddings?
Embeddings are dense numerical representations of text created by machine learning models. Modern embedding models are typically transformer-based neural networks trained on billions of text documents to understand language patterns, semantic relationships, and contextual meaning.
When you pass text through an embedding model, it outputs a vector—a fixed-length array of floating-point numbers. For example, OpenAI’s text-embedding-3-large model produces 3,072-dimensional vectors, while Google’s models might produce 768-dimensional vectors.
The magic happens in how these models are trained: they learn to position semantically similar content close together in vector space. Content about “machine learning algorithms” ends up near content about “neural network architectures” because the model has learned these concepts are semantically related.
Embedding Model Characteristics
Different embedding models have different characteristics that affect search quality:
Model size and dimensionality: Larger models with more dimensions generally capture more nuanced semantic distinctions but require more computational resources and storage.
Training data and domain: Models trained on general web text perform differently than models fine-tuned on scientific papers, legal documents, or code. Domain-specific embedding models often perform better for specialized content.
Multimodal capabilities: Advanced models can embed text, images, and other media into the same vector space, enabling cross-modal search (searching text to find relevant images, for example).
Contextualization: Modern embeddings are contextual—the same word gets different vectors based on surrounding context. “Bank” in “river bank” versus “savings bank” produces different embeddings.
The Importance of Semantic Density
For SEO teams, this means content optimization focuses on semantic density—how much meaningful, contextually rich information your content contains. Thin content produces weak embeddings that don’t retrieve well. Comprehensive, detailed content with clear semantic signals produces robust embeddings that match relevant queries effectively.
How LLMs Use Vector Search for Retrieval
Large Language Models like ChatGPT, Claude, and Gemini rely heavily on vector search for Retrieval-Augmented Generation (RAG)—the architecture that allows AI to cite sources, access current information, and ground responses in external knowledge.
The RAG Pipeline
Understanding the RAG pipeline helps SEO teams identify optimization opportunities:
1. Query Processing: When a user asks a question, the LLM analyzes the query to understand intent and extract key semantic concepts. It may reformulate or expand the query to improve retrieval.
2. Embedding Generation: The query (or its reformulated version) gets passed through an embedding model to create a query vector.
3. Vector Search: The system searches a vector database containing embedded documents, finding the K most similar content vectors (typically K=3-20 depending on the system).
4. Context Assembly: Retrieved content chunks get assembled into context that’s provided to the LLM alongside the original query.
5. Response Generation: The LLM generates a response using both its trained knowledge and the retrieved context, often citing specific sources.
6. Ranking and Filtering: Some systems apply additional ranking, filtering, or re-ranking steps to ensure retrieved content meets quality and relevance thresholds.
Implications for Content Strategy
This pipeline reveals critical optimization points:
Chunk-level optimization: Content gets broken into chunks (typically 200-1000 tokens) for indexing. Each chunk needs to be semantically self-contained and valuable on its own.
Context clarity: Chunks should include enough context that they make sense independently. Pronouns without clear antecedents or references to “the above section” create confusion when chunks are retrieved in isolation.
Query diversity coverage: Your content should semantically align with the various ways users might ask about your topic—not just keyword variations but conceptually different framings of similar questions.
Source quality signals: LLMs often evaluate source credibility when deciding whether to cite content. Clear authorship, citations, and quality signals matter more than ever.
Semantic Indexing: Building Discoverable Content
Semantic indexing refers to how AI systems organize and structure content for efficient vector retrieval. Understanding this process helps SEO teams structure content optimally.
Content Chunking Strategies
How your content gets divided into chunks significantly impacts retrievability. Most vector search systems chunk content before embedding, and chunk quality directly affects search performance.
Semantic chunking: Advanced systems attempt to chunk at natural semantic boundaries—paragraphs, sections, or topic shifts—rather than arbitrary character counts.
Overlapping chunks: Some systems create overlapping chunks to ensure context isn’t lost at boundaries. A section that gets cut mid-thought can still be retrieved via an overlapping chunk that includes the complete thought.
Hierarchical chunking: Progressive systems might create embeddings at multiple levels—paragraphs, sections, and full documents—enabling retrieval at different granularities.
For SEO teams: Structure content with clear section breaks, use descriptive headings that capture section meaning, and ensure paragraphs are cohesive units that make sense independently. Avoid writing where critical context is spread across distant paragraphs.
Metadata and Structured Information
Vector search systems often combine semantic embeddings with metadata filtering to improve precision:
Temporal metadata: Publication date, last update date, and temporal signals help systems retrieve current information when recency matters.
Categorical metadata: Tags, categories, content type classifications enable filtering before or after vector search.
Entity extraction: Systems extract and index named entities (people, organizations, locations, products) to enable entity-based filtering and retrieval.
Structural metadata: Document structure, heading hierarchies, and section classifications help systems understand content organization.
For SEO teams: Implement comprehensive structured data (Schema.org markup), maintain accurate metadata, use descriptive headings with clear semantic meaning, and organize content hierarchically with clear section demarcations.
Contextual Enrichment
Smart indexing systems enrich content with additional context before embedding:
Document context: Including document title, category, and author information alongside content chunks improves embedding quality.
Surrounding context: Including adjacent sections or paragraphs when embedding specific chunks provides better semantic representation.
Link context: Information about what content links to and from your page provides additional semantic signals.
For SEO teams: Ensure page titles and headings accurately describe content, build logical information architectures with clear topical relationships, and use descriptive link anchor text that provides semantic context.
Optimizing Content for Vector Search: Practical Strategies
Now we reach the actionable core: how SEO teams should actually optimize content for vector search systems.
1. Semantic Completeness Over Keyword Density
Traditional SEO focused on including target keywords at appropriate densities. Vector search requires semantic completeness—comprehensively covering the conceptual territory around your topic.
Cover related concepts: If writing about “email marketing,” naturally discuss related concepts like “subscriber engagement,” “open rates,” “A/B testing,” “deliverability,” and “list segmentation.” The vector embedding will reflect this comprehensive coverage.
Address related questions: Identify and answer the constellation of questions users might have around your topic. Tools like “People Also Ask” reveal these semantic clusters.
Define specialized terms: When using technical terminology, include clear definitions or explanations. This creates stronger embeddings and helps systems understand your content’s relationship to broader topics.
Provide examples and applications: Abstract concepts become more semantically rich when paired with concrete examples, use cases, and applications.
Practical implementation: Before publishing, audit content to identify semantic gaps—important related concepts, questions, or perspectives you haven’t addressed. Expand coverage to strengthen semantic representation.
2. Contextual Clarity and Self-Contained Sections
Since content gets chunked for vector indexing, every section should provide sufficient context to be understood independently.
Minimize unclear references: Avoid pronouns or phrases like “as mentioned above” that require reading previous chunks. If you must reference other sections, include enough context that the reference makes sense.
Front-load key information: Place the most important semantic signals early in sections so they’re included even if chunks are truncated.
Use descriptive headings: Headings should clearly indicate section content, providing context for the semantic content that follows.
Standalone value: Each section should deliver value independently. If a chunk gets retrieved in isolation, it should still meaningfully address the query it matched.
Practical implementation: Review each major section as if it were the only content a user would see. Does it provide enough context to be useful? Would a reader understand its relevance without reading other sections?
3. Question-Answer Optimization
Many queries to AI search systems are questions. Explicitly answering questions creates strong query-to-content semantic alignment.
Identify target questions: Research what questions users actually ask about your topic. Use tools, analyze search queries, and review forums and social media.
Provide clear answers: Don’t just discuss topics—explicitly answer questions. Use formats like “Q: [Question]? A: [Answer]” or “The answer is…” to create clear semantic signals.
Multiple question framings: Different users ask the same question differently. Address multiple framings: “How do I…?” “What’s the best way to…?” “Can you…?”
Progressive answer depth: Provide a direct answer followed by deeper explanation. This ensures simple queries retrieve quick answers while complex queries get comprehensive coverage.
Practical implementation: Create FAQ sections, embed questions in headings, and structure content around answering specific user questions rather than just covering topics.
4. Entity-Rich Content
Vector search systems understand entities—specific people, organizations, products, locations, concepts—and their relationships. Entity-rich content produces stronger embeddings.
Name entities explicitly: Use specific names rather than generic references. “Tesla Model 3” instead of “the electric car,” “Python 3.12” instead of “the programming language.”
Establish relationships: Explicitly state how entities relate to each other and to your main topic. These relationship signals strengthen semantic embeddings.
Define lesser-known entities: Don’t assume systems know niche entities. Provide brief context: “Anthropic, an AI safety company,” or “Tailwind CSS, a utility-first CSS framework.”
Consistent naming: Use entities’ standard names and include common variations to maximize semantic coverage.
Practical implementation: Audit content for generic references that could be replaced with specific entities. Implement schema markup for important entities to reinforce entity signals.
5. Comprehensive Topic Coverage
Vector embeddings reflect the breadth and depth of topic coverage. Comprehensive content produces richer embeddings that match more diverse queries.
Cover topic dimensions: Address multiple dimensions of your topic—technical details, practical applications, historical context, common challenges, best practices, and alternative approaches.
Include diverse perspectives: Present multiple viewpoints, approaches, or methodologies. This semantic diversity creates stronger, more robust embeddings.
Address edge cases and exceptions: Comprehensive coverage includes not just common scenarios but also special cases, exceptions, and nuanced situations.
Compare and contrast: Explicitly comparing your topic with related concepts, alternatives, or similar items enriches semantic understanding.
Practical implementation: Use topic modeling tools to identify semantic clusters within your subject area. Create content that systematically covers each cluster comprehensively.
6. Natural Language and Conversational Tone
Since many AI search queries are conversational questions, content written in natural, conversational language often performs better in vector search.
Conversational phrasing: Use natural language that mirrors how people actually speak and ask questions, not stilted “SEO-speak.”
Direct address: Writing in second person (“you should…”) often aligns better with how users frame queries than third person or passive voice.
Question anticipation: Frame sections around anticipated user questions using natural language: “You might be wondering…” or “A common question is…”
Avoid keyword stuffing artifacts: Unnatural keyword repetition and awkward phrasing designed for traditional SEO actually hurts vector embeddings by introducing semantic noise.
Practical implementation: Read content aloud. Does it sound like how a knowledgeable person would explain the topic in conversation? If not, revise for more natural flow.
7. Content Freshness and Temporal Signals
Vector search systems often combine semantic relevance with temporal signals. Content freshness affects retrievability for time-sensitive topics.
Clear publication dates: Display publication and update dates prominently. Many systems index this metadata alongside content.
Temporal context in content: When discussing events, statistics, or current state, include temporal context: “As of 2024…” or “According to 2023 data…”
Regular content updates: Update high-value content regularly, refreshing statistics, examples, and best practices. This maintains strong temporal signals.
Evergreen vs. timely content: Clearly differentiate between evergreen foundational content and timely analysis. Systems can then apply appropriate temporal weighting.
Practical implementation: Implement content maintenance schedules for important pages. Update at least quarterly for rapidly evolving topics, annually for slower-changing subjects.
8. Multimodal Optimization
Advanced vector search systems embed images, videos, and other media. Multimodal optimization strengthens overall content discoverability.
Descriptive alt text: Write alt text that captures semantic meaning, not just literal image descriptions. Focus on what the image communicates conceptually.
Image captions and surrounding text: Text immediately surrounding images gets strongly associated with image semantics. Use this context strategically.
Video transcripts: Provide complete, accurate transcripts for video content. These get embedded and enable retrieval of video content via text queries.
Descriptive filenames: Use semantically meaningful filenames for images and media files, not “IMG_1234.jpg.”
Practical implementation: Audit multimedia content for semantic richness. Ensure every image, video, and graphic has associated text that captures its semantic meaning.
Technical Implementation for SEO Teams
Understanding optimization strategies is valuable, but implementation requires technical considerations.
Content Management System Considerations
Your CMS architecture affects how well content can be optimized for vector search:
Structured content storage: Store content in structured formats that facilitate semantic chunking—separate fields for headings, body text, metadata, and media.
Metadata management: Implement comprehensive metadata capture—categories, tags, entities, temporal information, and authorship.
Version control: Track content changes over time so systems can access historical versions and understand content evolution.
API accessibility: Ensure content is accessible via APIs that search systems can crawl and index efficiently.
Preparing for Vector Indexing
While you can’t control external systems’ indexing, you can structure content to facilitate optimal indexing:
Clear HTML structure: Use semantic HTML5 elements (<article>, <section>, <aside>) that signal content structure.
Heading hierarchies: Implement proper H1-H6 hierarchies that reflect content organization and facilitate semantic chunking.
Schema markup: Implement comprehensive Schema.org markup to provide explicit semantic signals about content type, entities, and relationships.
Structured data for FAQs: Use FAQ schema to explicitly mark question-answer content, making it easier for systems to extract and index.
Monitoring and Measurement
Measuring vector search optimization requires different approaches than traditional SEO:
AI search visibility tracking: Monitor whether your content appears in AI search platforms like ChatGPT, Perplexity, and Google SGE for target queries.
Citation tracking: Track when and how AI systems cite your content. Tools are emerging to monitor these citations across platforms.
Content retrieval testing: Systematically test whether your content gets retrieved for relevant semantic queries, not just exact keyword matches.
Semantic ranking analysis: Analyze what content ranks for semantically related queries to understand competitive semantic positioning.
Vector Search in Different AI Platforms
Different AI platforms implement vector search with varying characteristics:
ChatGPT and OpenAI Search
OpenAI’s search implementation combines web retrieval with ChatGPT’s language understanding:
- Uses GPT-4-based query understanding and reformulation
- Retrieves from real-time web crawling plus partnership content
- Emphasizes source diversity and recency for current events
- Provides citations with direct links to source content
Optimization focus: Clear authorship, comprehensive coverage, regular updates, and explicit question answering.
Perplexity AI
Perplexity specializes in research-focused search with heavy vector retrieval:
- Emphasizes academic and authoritative sources
- Strong preference for recent, well-cited content
- Provides detailed source attribution
- Combines multiple sources to build comprehensive answers
Optimization focus: Academic rigor, comprehensive citations, data-driven content, and topical expertise.
Google SGE (Search Generative Experience)
Google’s AI search layers generative responses over traditional search:
- Combines vector search with traditional ranking signals
- Emphasizes E-E-A-T (Experience, Expertise, Authoritativeness, Trust)
- Maintains strong site reputation weighting
- Provides both AI-generated summaries and traditional result links
Optimization focus: Domain authority, comprehensive E-E-A-T signals, structured data, and traditional SEO fundamentals alongside semantic optimization.
Enterprise RAG Systems
Many organizations build internal RAG systems for proprietary content:
- Often use open-source embedding models and vector databases
- May implement custom chunking and indexing strategies
- Typically combine vector search with metadata filtering
- Performance varies significantly based on implementation quality
Optimization focus: Clear internal metadata, consistent formatting, comprehensive topic coverage, and structured document organization.
Common Pitfalls and How to Avoid Them
SEO teams transitioning to vector search optimization often encounter these challenges:
Pitfall 1: Keyword Thinking Persists
Problem: Teams continue optimizing for exact keyword matches rather than semantic coverage.
Solution: Shift KPIs from keyword rankings to semantic coverage metrics. Evaluate whether content comprehensively addresses the full conceptual territory around topics.
Pitfall 2: Ignoring Chunk-Level Optimization
Problem: Optimizing at page level while ignoring how content chunks individually when retrieved.
Solution: Review content at section level. Ensure each major section provides standalone value with sufficient context.
Pitfall 3: Over-Optimization and Semantic Noise
Problem: Attempting to manipulate vector embeddings through keyword stuffing or unnatural content leads to semantic noise that degrades embeddings.
Solution: Write naturally for humans. Trust that comprehensive, clear, natural language produces the best embeddings.
Pitfall 4: Neglecting Content Updates
Problem: Failing to update content as information changes or evolves leads to declining relevance in systems that weight recency.
Solution: Implement content maintenance schedules. Regularly update statistics, examples, and best practices in high-value content.
Pitfall 5: Insufficient Entity Coverage
Problem: Using generic references instead of specific entities creates weaker semantic signals.
Solution: Audit content for opportunities to replace generic references with specific entities, products, people, or organizations.
The Future of Vector Search and SEO
Vector search continues evolving rapidly. SEO teams should prepare for emerging trends:
Multimodal Search Expansion
Vector search will increasingly bridge modalities—searching text to find relevant images, videos, or audio content and vice versa. Content strategies must encompass optimization across all media types.
Personalized Vector Search
AI systems will generate personalized embeddings based on user context, history, and preferences. Content that serves diverse user perspectives and needs will perform better than narrowly focused content.
Real-Time Vector Indexing
As systems move toward real-time indexing, content freshness becomes even more critical. The gap between publication and discoverability will shrink dramatically.
Hybrid Search Architectures
Most production systems will combine vector search with keyword search, metadata filtering, and traditional ranking signals. Optimal content performs well across all these dimensions.
Quality-Weighted Embeddings
Emerging systems weight embeddings based on source quality, authority, and trustworthiness. E-E-A-T signals will directly influence vector search performance.
Conclusion: Embracing Semantic SEO
Vector search represents more than a technical evolution—it’s a philosophical shift in how content gets discovered. SEO teams must evolve from keyword optimizers to semantic strategists, from link builders to comprehensive content architects.
The good news: many vector search optimization principles align with creating genuinely valuable, user-focused content. Comprehensive topic coverage, clear writing, explicit question answering, and regular updates serve both users and vector search systems.
SEO teams that embrace semantic optimization early will establish competitive advantages as vector search becomes the dominant retrieval paradigm. Start now by:
- Auditing existing content for semantic completeness
- Restructuring content for chunk-level optimization
- Implementing comprehensive structured data and metadata
- Developing content that explicitly answers user questions
- Monitoring performance in AI search platforms
Vector search isn’t replacing traditional SEO—it’s expanding what SEO encompasses. The fundamentals remain: create valuable content that serves user needs. But the technical implementation of those fundamentals has evolved. SEO teams that understand and optimize for vector search will ensure their content remains discoverable in the AI-powered search era.
The future of search is semantic. The future of SEO is understanding and optimizing for that semantic reality.
Other great articles on AI, AEO & the Future of Marketing in the AI Age:
- 🚀 AEO PLAYBOOK 2026
- ✅ AEO (Answer Engine Optimization) & Every AI SEO Concept (2025 Master List)
- AI & Marketing in 2026: How Artificial Intelligence Is Redefining Strategy, Tools, and Results
- Should We Use AI in Content Marketing?
- How AI Search Engines Rank Content (Beyond Keywords & Backlinks)
- Entity-First SEO: Optimizing for Knowledge Graphs & AI Memory
- Search Without SERPs: How Zero-Click & Answer-Only Results Change SEO